Techletter #93 | October 5, 2024
Database indexing
Database indexing is one of the most important techniques when it comes to the performance of database queries. It just improves the speed of data retrieval from the table. Remember creating index will cost extra space. Ofcourse, it’s totally fine if we are saving the time.
So how does database indexing actually work? Before moving into database indexing there are some other topics that we need to understand.
Database and Database Management System
There exist a lot of confusion of what a databse is and what a database management system is. So let’s understand them before diving into indexing.
A database organizes data in a way that allows for easy access and management. This organization typically involves structuring data into tables, which consist of rows and columns, making it easier to query and manipulate the information stored within it.
While a database itself is simply the organized collection of data, a Database Management System (DBMS) is the software that manages this data. The DBMS provides tools for users to create, read, update, and delete data within the database.
Let’s understand with an example:
MySQL is a DBMS where as a database can be created within MySQL with the command CREATE DATABASE databasename;
The table that we see in the database within a DBMS is just a logical representation. So how is the data actually stored then?
Data Storage
DBMS creates Data Pages. A data page is a fundamental unit of data storage. And it stores rows of data in an organized manner. Let us understand data pages in an SQL server.
The data SQL Server logically stores in tables is physically stored on 8 KB data pages. (The size of the ****data page differs from database to database). This size dictates how many rows can be stored on a page, which depends on the size of each individual row.
Each data page starts with a 96-byte header that contains metadata about the page, such as the number of rows, the amount of free space available, and links to other pages if necessary
After the header, the actual data rows are stored serially. The rows begin immediately following the header, and their positions are tracked using a row offset table, which is located at the end of the page. This table contains entries that indicate how far each row is from the start of the page.
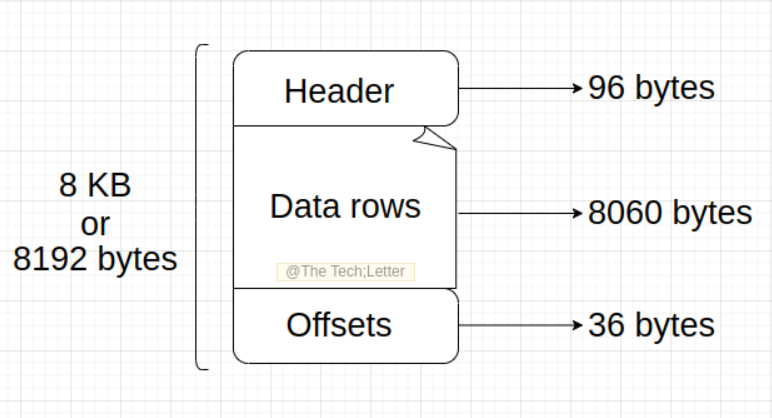
The offsets define the logical ordering of rows within the data page. Even if physical storage on the page appears scattered, the offset array maintains an ordered structure for how rows should be accessed.
The data page ultimately gets stored in a data block in physical memory. The DBMS maintains the mapping between the data page and the data block.
What is indexing?
As I mention this in the beginning, indexing is nothing but a technique that improves the performance of a database by reducing the number of disk accesses required when executing queries.
B-Trees and B+ Trees are essential data structures used in database indexing. B+ Tree is just an optimized version of B-Tree. I have linked a reference that better explains what B & B+ Trees are, you can go through it as database internals are very vast and can’t be explained in a single post. (I have to learn more about them too).
Two main types of indexing
-
Clustered indexing:
Clustered indexes sort and store the data rows in the table or view based on their key values. These key values are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be stored in only one order.
-
Non-clustered indexing:
Nonclustered indexes have a structure separate from the data rows. A nonclustered index contains the nonclustered index key values and each key value entry has a pointer to the data row that contains the key value.
SQL Server automatically creates indexes when PRIMARY KEY and UNIQUE constraints are defined on table columns. For example, when you create a table with a UNIQUE constraint, Database Engine automatically creates a nonclustered index. If you configure a PRIMARY KEY, Database Engine automatically creates a clustered index, unless a clustered index already exists.
There is more to database engineering. This was just my understanding of the subject this week. Hope, you did learn something new!!
References:
- https://medium.com/@hnasr/database-pages-a-deep-dive-38cdb2c79eb5
- Video reference
- https://www.sqlservercentral.com/articles/understanding-the-internals-of-a-data-page
- https://dgraph.io/blog/post/b-tree-vs-b+-tree/
- https://learn.microsoft.com/th-th/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described?view=sql-server-ver16