Techletter #66 | March 30th, 2024
What are database storage engines?
Storage engines in database management systems are software components responsible for handling SQL operations. They are responsible for creating, reading, updating, and deleting.
Each storage engines are tailored for specific needs.
For example, InnoDB is a popular choice due to its support for transactions, foreign keys, and row-level locking, ensuring data consistency and multi-user performance. MyISAM, on the other hand, is known for its simplicity and speed but lacks support for foreign keys.
What is the difference between local storage and session storage?
Local storage:
Local storage refers to a web storage type that allows JavaScript sites and apps to store data in the browser with no expiration date.
The data in local storage persists until it is explicitly deleted.
It is ideal for storing long-term data such as user preferences, settings, and other cache data.
Session storage:
Session storage is a type of web storage that allows data to be stored locally and securely within a user’s browser for the duration of a single session.
The session storage lasts until the tab is active, once you close the tab, your session storage is lost.
Session storage is suitable for temporary data storage needed during a browsing session, like storing information temporarily while navigating a website or completing multi-step processes within a single instance.
How does try/catch work in JavaScript?
Error handling is very important. Why? Imagine you are making a payment, and an error occurred while making the payment, but the success message is returned to the front end. Then it creates a great problem for the users, and they just lose trust in your software. Earning back the user’s trust is more hard than building software.
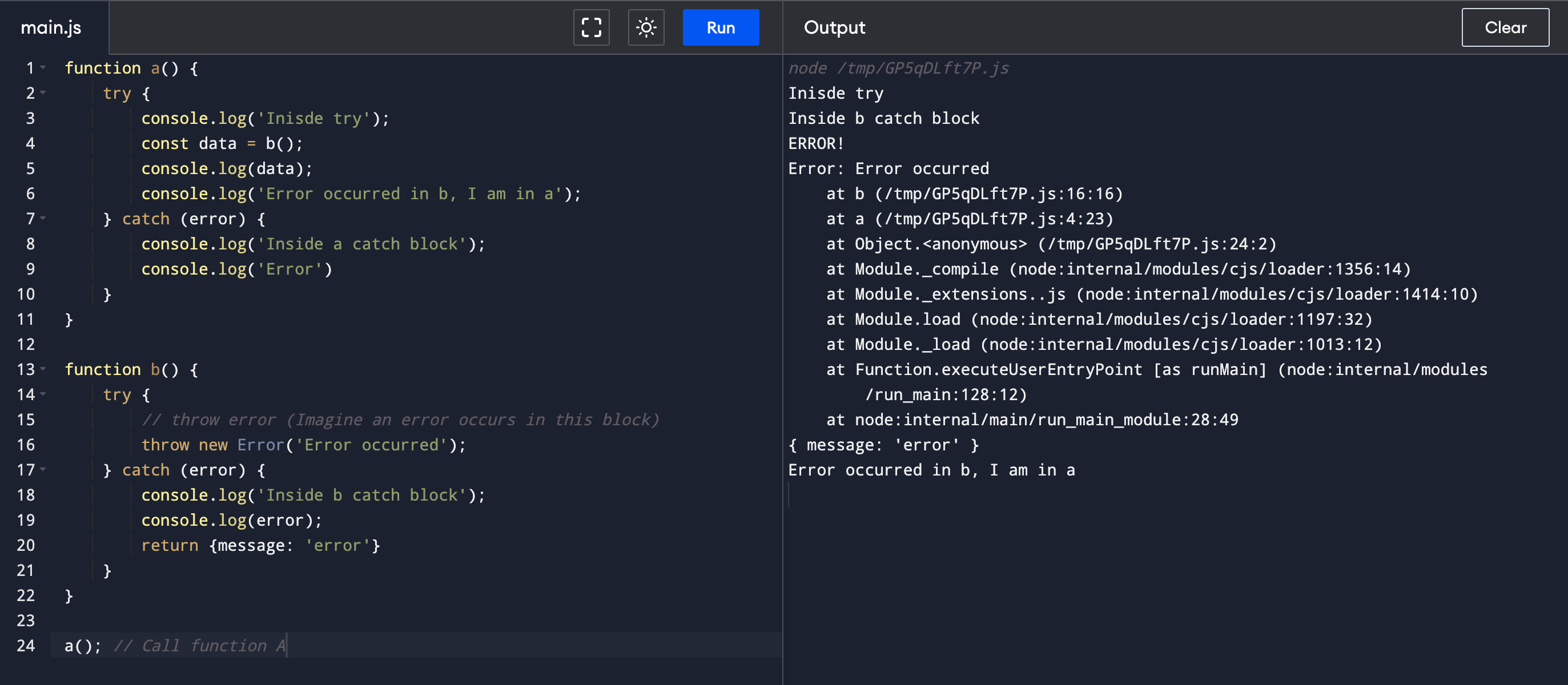
Let’s see how the error handling works in a try-catch block
function a() {
try {
console.log('Inisde try');
const data = b();
console.log(data);
console.log('Error occurred in b, I am in a');
} catch (error) {
console.log('Inside a catch block');
console.log('Error')
}
}
function b() {
try {
// throw error (Imagine an error occurs in this block)
throw new Error('Error occurred');
} catch (error) {
console.log('Inside b catch block');
console.log(error);
return {message: 'error'}
}
}
a(); // Call function A
Explanation:
Assume you have two functions A and B. Function B is called in function A. The error is thrown in function b. So now where does the error go? What is returned? Will the complete process be stopped?
Once the error is thrown in function B, it enters the catch block of function B and returns {message: ‘error’}. This return is stored in the variable data in function A.
The catch block is activated only in the function where the error is thrown. Not at all places where the function is called.
If run the above code, you will understand what exactly is happening.
OpenSearch Mappings
This is an insight that I got while working with OpenSearch and logstash. If you are working on this, then do remember that the data that you store in OpenSearch must be mapped correctly. A wrong data type will add a record but doesn’t get indexed.
For example, if you add an index called emails, your id is a string while mapping, but while adding data to the index if you add an id as a string, the data will get added to an index, but it won’t get indexed because of data mismatch. At least I experienced it while writing this. It took me early 2 hours to debug the exact issue.
What is the difference between useState and useRef in react?
From the docs:
useState() is a React Hook that lets you add a state variable to your component.
useRef() is a React Hook that lets you reference a value that’s not needed for rendering.